Используемые термины: Kubernetes, Ubuntu, Docker.
Есть различные готовые реализации кластера Kubernetes, например:
- Minikube — готовый кластер, который разворачивается на один компьютер. Хороший способ познакомиться с Kubernetes.
- Kubespray — набор Ansible ролей.
- Готовые кластеры в облаке, например AWS, Google Cloud, Yandex Cloud и так далее.
Использовать одну из готовых реализаций — быстрый и надежный способ развертывания системы оркестрации контейнеров Docker. Однако, мы рассмотрим ручное создание кластера Kubernetes из 3-х нод — один мастер (управление) и две рабочие ноды (запуск контейнеров).
Для этого выполним следующие шаги:
- Подготовка системы
- Настройка системы
- Брандмауэр
- Установка и настройка Docker
- Установка Kubernetes
- Создание кластера
- Настройка control-plane (мастер ноды)
- Настройка worker (рабочей ноды)
- Pods
- Создание
- Просмотр
- Запуск команд внутри контейнера
- Удаление
- Использование манифестов
- Deployments
- Создание
- Просмотр
- Scaling
- Редактирование
- Манифест
- Удаление
- Манифест
- Ingress Controller
- Установка веб-интерфейса
- Удаление нод
Подготовка системы
Данные действия выполняем на всех узлах будущего кластера. Это необходимо, чтобы удовлетворить программные системные требования для нашего кластера.
Настройка системы
1. Задаем имена узлам. Для этого выполняем команды на соответствующих серверах:
hostnamectl set-hostname k8s-master1.it-systems.local
hostnamectl set-hostname k8s-worker1.it-systems.local
hostnamectl set-hostname k8s-worker2.it-systems.local
* в данном примере мы зададим имя k8s-master1 для мастера и, соответственно, k8s-worker1 и k8s-worker2 — для первого и второго рабочих нод. Каждая команда выполняется на своем сервере.
Необходимо, чтобы наши серверы были доступны по заданным именам. Для этого необходимо на сервере DNS добавить соответствующие А-записи. Или на каждом сервере открываем hosts:
vi /etc/hostsИ добавляем записи на подобие:
192.168.0.15 k8s-master1.it-systems.local k8s-master1
192.168.0.20 k8s-worker1.it-systems.local k8s-worker1
192.168.0.25 k8s-worker2.it-systems.local k8s-worker2* где, 192.168.0.15, 192.168.0.20, 192.168.0.25 — IP-адреса наших серверов, k8s-master1, k8s-worker1, k8s-worker2 — имена серверов, it-systems.local — наш внутренний домен.
2. Устанавливаем необходимые компоненты — дополнительные пакеты и утилиты. Для начала, обновим список пакетов и саму систему:
apt-get update && apt-get upgradeВыполняем установку пакетов:
apt-get install curl apt-transport-https git iptables-persistent* где:
- git — утилита для работы с GIT. Понадобиться для загрузки файлов из репозитория git.
- curl — утилита для отправки GET, POST и других запросов на http-сервер. Понадобиться для загрузки ключа репозитория Kubernetes.
- apt-transport-https — позволяет получить доступ к APT-репозиториям по протоколу https.
- iptables-persistent — утилита для сохранения правил, созданных в iptables (не обязательна, но повышает удобство).
В процессе установки iptables-persistent может запросить подтверждение сохранить правила брандмауэра — отказываемся.
3. Отключаем файл подкачки. С ним Kubernetes не запустится.
Выполняем команду для разового отключения:
swapoff -aЧтобы swap не появился после перезагрузки сервера, открываем на редактирование файл:
vi /etc/fstabИ комментируем строку:
#/swap.img none swap sw 0 0Загружаем дополнительные модули ядра.
vi /etc/modules-load.d/k8s.confbr_netfilter
overlay* модуль br_netfilter расширяет возможности netfilter (подробнее); overlay необходим для Docker.
Загрузим модули в ядро:
modprobe br_netfilter
modprobe overlay
Проверяем, что данные модули работают:
lsmod | egrep "br_netfilter|overlay"
Мы должны увидеть что-то на подобие:
overlay 114688 10
br_netfilter 28672 0
bridge 176128 1 br_netfilter5. Изменим параметры ядра.
Создаем конфигурационный файл:
vi /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1* net.bridge.bridge-nf-call-iptables контролирует возможность обработки трафика через bridge в netfilter. В нашем примере мы разрешаем данную обработку для IPv4 и IPv6.
Применяем параметры командой:
sysctl --system
Брандмауэр
Для мастер-ноды и рабочей создаем разные наборы правил.
По умолчанию, в Ubuntu брандмауэр настроен на разрешение любого трафика. Если мы настраиваем наш кластер в тестовой среде, настройка брандмауэра не обязательна.
1. На мастер-ноде (Control-plane)
Выполняем команду:
iptables -I INPUT 1 -p tcp --match multiport --dports 6443,2379:2380,10250:10252 -j ACCEPT* в данном примере мы открываем следующие порты:
- 6443 — подключение для управления (Kubernetes API).
- 2379:2380 — порты для взаимодействия мастера с воркерами (etcd server client API).
- 10250:10252 — работа с kubelet (соответственно API, scheduler, controller-manager).
Для сохранения правил выполняем команду:
netfilter-persistent save
2. На рабочей ноде (Worker):
На нодах для контейнеров открываем такие порты:
iptables -I INPUT 1 -p tcp --match multiport --dports 10250,30000:32767 -j ACCEPT
* где:
- 10250 — подключение к kubelet API.
- 30000:32767 — рабочие порты по умолчанию для подключения к подам (NodePort Services).
Сохраняем правила командой:
netfilter-persistent save
Установка и настройка Docker
На все узлы кластера выполняем установку Docker следующей командой:
apt-get install docker docker.ioПосле установки разрешаем автозапуск сервиса docker:
systemctl enable dockerСоздаем файл:
vi /etc/docker/daemon.json{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}* для нас является важной настройкой cgroupdriver — она должна быть выставлена в значение systemd. В противном случае, при создании кластера Kubernetes выдаст предупреждение. Хоть на возможность работы последнего это не влияет, но мы постараемся выполнить развертывание без ошибок и предупреждений со стороны системы.
И перезапускаем docker:
systemctl restart dockerУстановка Kubernetes
Установку необходимых компонентов выполним из репозитория. Добавим его ключ для цифровой подписи:
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
Создадим файл с настройкой репозитория:
vi /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
Обновим список пакетов:
apt-get updateУстанавливаем пакеты:
apt-get install kubelet kubeadm kubectl* где:
- kubelet — сервис, который запускается и работает на каждом узле кластера. Следит за работоспособностью подов.
- kubeadm — утилита для управления кластером Kubernetes.
- kubectl — утилита для отправки команд кластеру Kubernetes.
Нормальная работа кластера сильно зависит от версии установленных пакетов. Поэтому бесконтрольное их обновление может привести к потере работоспособности всей системы. Чтобы этого не произошло, запрещаем обновление установленных компонентов:
apt-mark hold kubelet kubeadm kubectlУстановка завершена — можно запустить команду:
kubectl version --client… и увидеть установленную версию программы:
Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.2", GitCommit:"faecb196815e248d3ecfb03c680a4507229c2a56", GitTreeState:"clean", BuildDate:"2021-01-13T13:28:09Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"linux/amd64"}
Наши серверы готовы к созданию кластера.
Создание кластера
По-отдельности, рассмотрим процесс настройки мастер ноды (control-plane) и присоединения к ней двух рабочих нод (worker).
Настройка control-plane (мастер ноды)
Выполняем команду на мастер ноде:
kubeadm init --pod-network-cidr=10.244.0.0/16
* данная команда выполнит начальную настройку и подготовку основного узла кластера. Ключ —pod-network-cidr задает адрес внутренней подсети для нашего кластера.
Выполнение займет несколько минут, после чего мы увидим что-то на подобие:
...
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.15:6443 --token f7sihu.wmgzwxkvbr8500al \
--discovery-token-ca-cert-hash sha256:6746f66b2197ef496192c9e240b31275747734cf74057e04409c33b1ad280321* данную команду нужно вводить на worker нодах, чтобы присоединить их к нашему кластеру. Можно ее скопировать, но позже мы будем генерировать данную команду по новой.
В окружении пользователя создаем переменную KUBECONFIG, с помощью которой будет указан путь до файла конфигурации kubernetes:
export KUBECONFIG=/etc/kubernetes/admin.conf
Чтобы каждый раз при входе в систему не приходилось повторять данную команду, открываем файл:
vi /etc/environment
И добавляем в него строку:
export KUBECONFIG=/etc/kubernetes/admin.confПосмотреть список узлов кластера можно командой:
kubectl get nodesНа данном этапе мы должны увидеть только мастер ноду:
NAME STATUS ROLES AGE VERSION
k8s-master.it-systems.local NotReady <none> 10m v1.20.2Чтобы завершить настройку, необходимо установить CNI (Container Networking Interface) — в моем примере это flannel:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml* краткий обзор и сравнение производительности CNI можно почитать в статье на хабре.
Узел управления кластером готов к работе.
Настройка worker (рабочей ноды)
Мы можем использовать команду для присоединения рабочего узла, которую мы получили после инициализации мастер ноды или вводим (на первом узле):
kubeadm token create --print-join-commandДанная команда покажет нам запрос на присоединения новой ноды к кластеру, например:
kubeadm join 192.168.0.15:6443 --token f7sihu.wmgzwxkvbr8500al \
--discovery-token-ca-cert-hash sha256:6746f66b2197ef496192c9e240b31275747734cf74057e04409c33b1ad280321Копируем его и используем на двух наших узлах. После завершения работы команды, мы должны увидеть:
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
На мастер ноде вводим:
kubectl get nodesМы должны увидеть:
NAME STATUS ROLES AGE VERSION
k8s-master1.dmosk.local Ready control-plane,master 18m v1.20.2
k8s-worker1.dmosk.local Ready <none> 79s v1.20.2
k8s-worker2.dmosk.local Ready <none> 77s v1.20.2Наш кластер готов к работе. Теперь можно создавать поды, развертывания и службы. Рассмотрим эти процессы подробнее.
Pods
Поды — неделимая сущность объекта в Kubernetes. Каждый Pod может включать в себя несколько контейнеров (минимум, 1). Рассмотрим несколько примеров, как работать с подами. Все команды выполняем на мастере.
Создание
Поды создаются командой kubectl, например:
kubectl run nginx --image=nginx:latest --port=80* в данном примере мы создаем под с названием nginx, который в качестве образа Docker будет использовать nginx (последнюю версию); также наш под будет слушать запросы на порту 80.
Чтобы получить сетевой доступ к созданному поду, создаем port-forward следующей командой:
kubectl port-forward nginx --address 0.0.0.0 8888:80* в данном примере запросы к кластеру kubernetes на порт 8888 будут вести на порт 80 (который мы использовали для нашего пода).
Команда kubectl port-forward является интерактивной. Ее мы используем только для тестирования. Чтобы пробросить нужные порты в Kubernetes используются Services — об этом будет сказано ниже.
Можно открыть браузер и ввести адрес http://<IP-адрес мастера>:8888 — должна открыться страница приветствия для NGINX.
Просмотр
Получить список всех подов в кластере можно командой:
kubectl get podsНапример, в нашем примере мы должны увидеть что-то на подобие:
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 3m26sПосмотреть подробную информацию о конкретном поде можно командой:
kubectl describe pods nginxЗапуск команд внутри контейнера
Мы можем запустить одну команду в контейнере, например, такой командой:
kubectl exec nginx -- date* в данном примере будет запущена команда date внутри контейнера nginx.
Также мы можем подключиться к командной строке контейнера командой:
kubectl exec --tty --stdin nginx -- /bin/bashУдаление
Для удаления пода вводим:
kubectl delete pods nginxИспользование манифестов
В продуктивной среде управление подами выполняется с помощью специальных файлов с описанием того, как должен создаваться и настраиваться под — манифестов. Рассмотрим пример создания и применения такого манифеста.
Создадим файл формата yml:
vi manifest_pod.yamlapiVersion: v1
kind: Pod
metadata:
name: web-srv
labels:
app: web_server
owner: dmosk
description: web_server_for_site
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
- containerPort: 443
- name: php-fpm
image: php-fpm:latest
ports:
- containerPort: 9000
- name: mariadb
image: mariadb:latest
ports:
- containerPort: 3306* в данном примере будет создан под с названием web-srv; в данном поде будет развернуто 3 контейнера — nginx, php-fpm и mariadb на основе одноименных образов.
Для объектов Kubernetes очень важное значение имеют метки или labels. Необходимо всегда их описывать. Далее, данные метки могут использоваться для настройки сервисов и развертываний.
Чтобы применить манифест выполняем команду:
kubectl apply -f manifest_pod.yamlМы должны увидеть ответ:
pod/web-srv createdСмотрим поды командой:
kubectl get podsМы должны увидеть:
NAME READY STATUS RESTARTS AGE
web-srv 3/3 Ready 0 3m11s* для Ready мы можем увидеть 0/3 или 1/3 — это значит, что контейнеры внутри пода еще создаются и нужно подождать.
Deployments
Развертывания позволяют управлять экземплярами подов. С их помощью контролируется их восстановление, а также балансировка нагрузки. Рассмотрим пример использования Deployments в Kubernetes.
Создание
Deployment создаем командой со следующим синтаксисом:
kubectl create deploy <название для развертывания> --image <образ, который должен использоваться>Например:
kubectl create deploy web-set --image nginx:latest* данной командой мы создадим deployment с именем web-set; в качестве образа будем использовать nginx:latest.
Просмотр
Посмотреть список развертываний можно командой:
kubectl get deployПодробное описание для конкретного развертывания мы можем посмотреть так:
kubectl describe deploy web-set* в данном примере мы посмотрим описание deployment с названием web-set.
Scaling
Как было написано выше, deployment может балансировать нагрузкой. Это контролируется параметром scaling:
kubectl scale deploy web-set --replicas 3* в данном примере мы указываем для нашего созданного ранее deployment использовать 3 реплики — то есть Kubernetes создаст 3 экземпляра контейнеров.
Также мы можем настроить автоматическую балансировку:
kubectl autoscale deploy web-set --min=5 --max=10 --cpu-percent=75В данном примере Kubernetes будет создавать от 5 до 10 экземпляров контейнеров — добавление нового экземпляра будет происходить при превышении нагрузки на процессор до 75% и более.
Посмотреть созданные параметры балансировки можно командой:
kubectl get hpaРедактирование
Для нашего развертывания мы можем изменить используемый образ, например:
kubectl set image deploy/web-set nginx=httpd:latest --record* данной командой для deployment web-set мы заменим образ nginx на httpd; ключ record позволит нам записать действие в историю изменений.
Если мы использовали ключ record, то историю изменений можно посмотреть командой:
kubectl rollout history deploy/web-setПерезапустить deployment можно командой:
kubectl rollout restart deploy web-setМанифест
Как в случае с подами, для создания развертываний мы можем использовать манифесты. Попробуем рассмотреть конкретный пример.
Создаем новый файл:
vi manifest_deploy.yamlapiVersion: apps/v1
kind: Deployment
metadata:
name: web-deploy
labels:
app: web_server
owner: it-systems
description: web_server_for_site
spec:
replicas: 5
selector:
matchLabels:
project: myweb
template:
metadata:
labels:
project: myweb
owner: it-systems
description: web_server_pod
spec:
containers:
- name: myweb-httpd
image: httpd:latest
ports:
- containerPort: 80
- containerPort: 443
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: web-deploy-autoscaling
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myweb-autoscaling
minReplicas: 5
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 75
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80* в данном манифесте мы создадим deployment и autoscaling. Итого, мы получим 5 экземпляров подов для развертывания web-deploy, которые могут быть расширены до 10 экземпляров. Добавление нового будет происходить при превышении нагрузки на процессор более чем на 75% или потреблением оперативной памяти более чем на 80%.
Чтобы создать объекты с помощью нашего манифеста вводим:
kubectl apply -f manifest_deploy.yamlМы должны увидеть:
deployment.apps/web-deploy created
horizontalpodautoscaler.autoscaling/web-deploy-autoscaling createdОбъекты web-deploy и web-deploy-autoscaling созданы.
Удаление
Для удаления конкретного развертывания используем команду:
kubectl delete services web-deploy* в данном примере будет удалена служба для развертывания web-deploy.
Удалить все службы можно командой:
kubectl delete services --allМанифест
Как в случае с подами и развертываниями, мы можем использовать манифест-файлы. Рассмотрим небольшой пример.
vi manifest_service.yamlapiVersion: v1
kind: Service
metadata:
name: web-service
labels:
app: web_server
owner: it-systems
description: web_server_for_site
spec:
selector:
project: myweb
type: NodePort
ports:
- name: app-http
protocol: TCP
port: 80
targetPort: 80
- name: app-smtp
protocol: TCP
port: 25
targetPort: 25* в данном примере мы создадим службу, которая будем связываться с развертыванием по лейболу project: myweb.
Ingress Controller
В данной инструкции не будет рассказано о работе с Ingress Controller. Оставляем данный пункт для самостоятельного изучения.
Данное приложение позволяет создать балансировщик, распределяющий сетевые запросы между нашими сервисами. Порядок обработки сетевого трафика определяем с помощью Ingress Rules.
Существует не маленькое количество реализаций Ingress Controller — их сравнение можно найти в документе по ссылке в Google Docs.
Для установки Ingress Controller Contour (среди множества контроллеров, он легко устанавливается и на момент обновления данной инструкции полностью поддерживает последнюю версию кластера Kubernetes) вводим:
kubectl apply -f https://projectcontour.io/quickstart/contour.yamlУстановка веб-интерфейса
Веб-интерфейс позволяет получить информацию о работе кластера в удобном для просмотра виде.
В большинстве инструкций рассказано, как получить доступ к веб-интерфейсу с того же компьютера, на котором находится кластер (по адресу 127.0.0.1 или localhost). Но мы рассмотрим настройку для удаленного подключения, так как это более актуально для серверной инфраструктуры.
Переходим на страницу веб-интерфейса в GitHub и копируем ссылку на последнюю версию файла yaml:

* на момент обновления инструкции, последняя версия интерфейса была 2.1.0.
Скачиваем yaml-файл командой:
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.1.0/aio/deploy/recommended.yaml* где https://raw.githubusercontent.com/kubernetes/dashboard/v2.1.0/aio/deploy/recommended.yaml — ссылка, которую мы скопировали на портале GitHub.
Открываем на редактирование скачанный файл:
vi recommended.yamlКомментируем строки для kind: Namespace и kind: Secret (в файле несколько блоков с kind: Secret — нам нужен тот, что с name: kubernetes-dashboard-certs):
...
#apiVersion: v1
#kind: Namespace
#metadata:
# name: kubernetes-dashboard
...
#apiVersion: v1
#kind: Secret
#metadata:
# labels:
# k8s-app: kubernetes-dashboard
# name: kubernetes-dashboard-certs
# namespace: kubernetes-dashboard
#type: Opaque* нам необходимо закомментировать эти блоки, так как данные настройки в Kubernetes мы должны будем сделать вручную.
Теперь в том же файле находим kind: Service (который с name: kubernetes-dashboard) и добавляем строки type: NodePort и nodePort: 30001 (выделены жирным):
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30001
selector:
k8s-app: kubernetes-dashboard* таким образом, мы публикуем наш сервис на внешнем адресе и порту 30001.
Для подключения к веб-интерфейсу не через локальный адрес, начиная с версии 1.17, обязательно необходимо использовать зашифрованное подключение (https). Для этого нужен сертификат. В данной инструкции мы сгенерируем самоподписанный сертификат — данный подход удобен для тестовой среды, но в продуктивной среде необходимо купить сертификат или получить его бесплатно в Let’s Encrypt.
И так, создаем каталог, куда разместим наши сертификаты:
mkdir -p /etc/ssl/kubernetesСгенерируем сертификаты командой:
openssl req -new -x509 -days 1461 -nodes -out /etc/ssl/kubernetes/cert.pem -keyout /etc/ssl/kubernetes/cert.key -subj "/C=RU/ST=SPb/L=SPb/O=Global Security/OU=IT Department/CN=kubernetes.it-systems.local/CN=kubernetes"* можно не менять параметры команды, а так их и оставить. Браузер все-равно будет выдавать предупреждение о неправильном сертификате, так как он самоподписанный.
Создаем namespace:
kubectl create namespace kubernetes-dashboard* это та первая настройка, которую мы комментировали в скачанном файле recommended.yaml.
Теперь создаем настройку для secret с использованием наших сертификатов:
kubectl create secret generic kubernetes-dashboard-certs --from-file=/etc/ssl/kubernetes/cert.key --from-file=/etc/ssl/kubernetes/cert.pem -n kubernetes-dashboard* собственно, мы не использовали настройку в скачанном файле, так как создаем ее с включением в параметры пути до созданных нами сертификатов.
Теперь создаем остальные настройки с помощью скачанного файла:
kubectl create -f recommended.yamlМы увидим что-то на подобие:
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper createdСоздадим настройку для админского подключения:
vi dashboard-admin.yamlapiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: dashboard-admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin-bind-cluster-role
labels:
k8s-app: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kubernetes-dashboardСоздаем настройку с применением созданного файла:
kubectl create -f dashboard-admin.yamlТеперь открываем браузер и переходим по ссылке https://<IP-адрес мастера>:30001 — браузер покажет ошибку сертификата (если мы настраиваем по инструкции и сгенерировали самоподписанный сертификат). Игнорируем ошибку и продолжаем загрузку.
Kubernetes Dashboard потребует пройти проверку подлинности. Для этого можно использовать токен или конфигурационный файл:
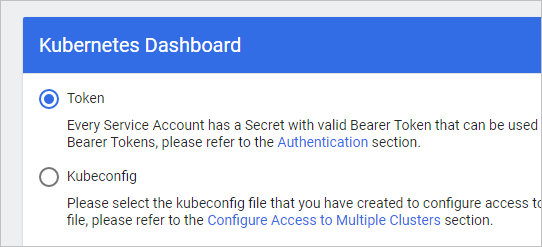
На сервере вводим команду для создания сервисной учетной записи:
kubectl create serviceaccount dashboard-admin -n kube-systemСоздадим привязку нашего сервисного аккаунта с Kubernetes Dashboard:
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-adminТеперь камандой:
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}'получаем токен для подключения
Используя полученный токен, вводим его в панели авторизации:
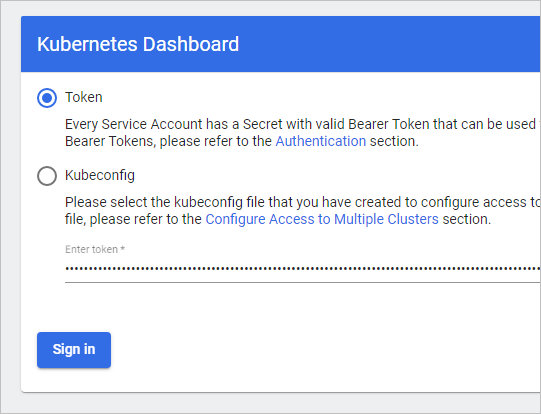
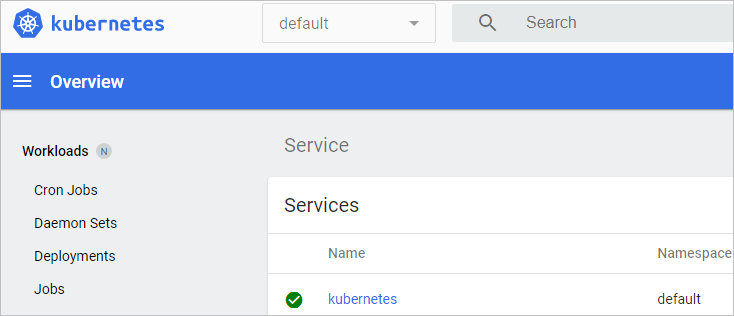
Мы должны увидеть стартовое окно системы управления:
Удаление нод
При необходимости удалить ноду из нашего кластера, вводим 2 команды:
kubectl drain k8s-worker2.it-systems.local --ignore-daemonsetskubectl delete node k8s-worker2.it-systems.local
* в данном примере мы удаляем ноду k8s-worker2.it-systems.local.




